Введение
Мы рассмотрим алгоритм классификации k-ближайших соседей (kNN), который представляет собой очень простой алгоритм с обучением на примерах. Несмотря на простоту на определенных классах задач он показывает очень хорошую эффективность. Мы рассмотрим алгоритм в общих чертах, объясним соответствующие параметры и реализации.
k-Nearest Neighbors
Алгоритм kNN, как и другие алгоритмы с обучением на примерах, необычен с точки зрения классификации, вследствие отсутствия явного обучения модели. Хотя для него требуется обучающая выборка, она используется исключительно для заполнения образца в пространстве поиска экземплярами, чей класс известен. Реального моделирования или обучения на данном этапе не производится, поэтому такие алгоритмы известны как "ленивые". В зависимости от природы данных могут использоваться различные метрики расстояния между объектами. Для непрерывных переменных обычно используется евклидово расстояние, для категорийных данных часто используются другие метрики. Для специфичных задач, таких как классификация текста, часто полезны специфичные метрики. Когда объект, чья принадлежность к определенному классу неизвестна, предъявляется для классификации, алгоритм рассчитывает его k ближайших соседей, и класс присваивается голосованием среди этих соседей.
Для предотвращения ошибок при бинарной классификации обычно выбирается нечетное k. Для нескольких классов может использоваться относительное или мажоритарное большинство. В последнем случае объект может не быть отнесенным ни к какому классу, в то время как при использовании первого метода может быть получена очень слабая поддержка от соседа. Можно также присвоить каждому соседу вес, обратный расстоянию до него от классифицируемого объекта.
Главные преимущества kNN при классификации:
- очень простая реализация;
- надежен по отношению к пространству поиска;
- классификатор можно обновить на лету с очень маленькими затратами при поступлении новых экземпляров объектов известных классов;
- небольшое количество параметров для настройки: метрика расстояния и k.
Главные недостатки алгоритма:
- затратное обучение каждого объекта, так как необходимо рассчитывать его расстояние до всех известных объектов. Для конкретных задач и метрик имеются специализированные алгоритмы и эвристики, которые помогают облегчить эту задачу. Но это проблематично для наборов данных с большим количеством признаков. Если количество объектов намного больше, чем количество признаков, для хранения объектов может использоваться R-дерево или kd-дерево, что позволяет быстрее идентифицировать соседей.
- чувствительность к шуму или не относящимся к делу признакам, которые могут сделать расстояние менее значимым. Обычно для смягчения этой проблемы используются масштабирование и/или выборка признаков.
- чувствительность к сильно несбалансированным данным, где большинство объектов принадлежит к одному или немногим классам, поэтому нечасто встречающиеся классы зачастую подавляются большинством соседей. Эта проблема облегчается путем сбалансированного отбора более популярных классов в обучающей выборке.
Описание алгоритма
Этап обучения для kNN состоит из простого хранения всех известных объектов и меток их классов. Может использоваться табличное представление или специализированные структуры, такие как kd-дерево. Если мы хотим настроить значение k и/или выполнить отбор признаков, на обучающей выборке можно выполнить n-фолдную кросс-валидацию. В известной выборке "I" этап обучения для нового объекта "t" производится следующим образом:
- рассчитывается расстояние между "t" и каждым объектом из "I";
- сортировка расстояний по возрастанию и выбор первых "k" элементов;
- расчет и возвращения наиболее часто встречающегося среди "k" ближайших соседей класса, опционально взвешивание класса каждого объекта величиной, обратной расстоянию до "t".
Имеющиеся реализации
На сегодняшний день имеется по крайней мере три реализации классификации kNN для R, доступные в CRAN:
- knn;
- kknn;
RWeka, которая является интерфейсом к популярному тулкиту WEKA и помимо kNN предоставляет доступ к десяткам алгоритмов класификации, кластеризации, регрессии и т.д.
Для этого руководства мы выбираем RWeka, так как она предлагает намного большую, чем простая классификация kNN, функциональность.
Установка и запуск RWeka
RWeka - это пакет из CRAN, поэтому мы его можем очень просто установить в R:
install.packages("RWeka", dependencies = TRUE)
После установки RWeka необходимо загрузить в рабочее пространство:
library(RWeka)
Она поставляется с несколькими хорошо известными наборами данных, которые можно загрузить из файлов ARFF (стандартный формат файлов Weka). Сейчас мы загрузим простой и широко известный набор данных Iris, и обучим для него классификатор kNN, используя параметры по умолчанию:
Хотя здесь мы использовали только параметры по умолчанию, RWeka позволяет нам настраивать классификатор KNN несколькими способами, помимо изменения значения k:
- мы можем взвешивать соседей величинами, обратными расстояниям до целевого объекта, или (1 - расстояние);
- мы можем использовать кросс-валидацию для выбора оптимального значения k на обучающей выборке;
- мы можем использовать скользящее окно обучающих объектов, то есть классификатор знает в каждый момент времени о W объектах, старые объекты отбрасываются, новые добавляются;
- мы можем настраивать способ хранения известных объектов, что позволяет нам использовать kd-деревья и другие похожие структуры для более быстрого поиска соседей в больших наборах данных.
Пример
Теперь мы выполним более детальное исследование набора данных Iris, используя кросс-валидацию для реального обучения, а также настроим некоторые параметры.
Набор данных
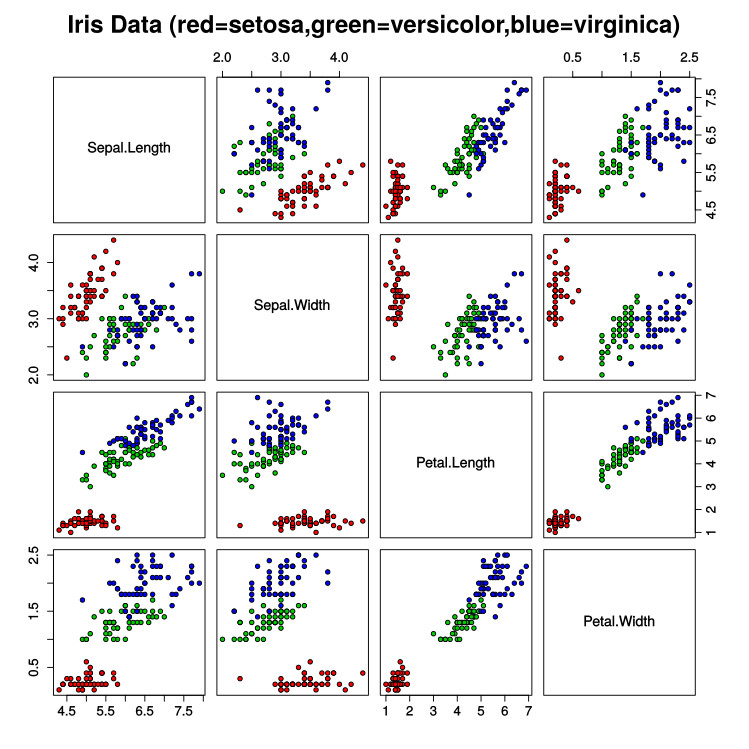
Набор данных Iris включает 150 объектов, относящихся к трем, встречающимся с одинаковой частотой видам ирисов (Iris setosa, Iris versicolour и Iris virginica). Ниже вы можете посмотреть, как выглядит ирис.

Каждый объект имеет четыре признака: sepal length в см, sepal width в см, petal length в см и petal width в см. Ниже приведены графики признаков попарно, с обозначением классов различными цветами.
Результаты
Мы генерируем классификатор kNN, но при этом позволяем RWeka автоматически найти лучшее значение k в диапазоне от 1 до 20. Мы также используем 10-фолдную кросс-валидацию для оценки нашего классификатора.
Поскольку для кросс-валидации используются случайные участки набора данных, ваши результаты могут отличаться. Однако обычно модель делает меньше 10 ошибок.
Анализ результатов
Этот простой пример показывает, что классификатор kNN сделал несколько ошибок на нашем наборе данных, который, несмотря на простоту, не является линейно разделимым, что можно видеть на точечных графиках. Матрица невязок показывает, что все ошибки классификации возникают между объектами Iris Versicolor и Iris Virginica. Наш пример также показал, что RWeka позволяет очень просто производить обучение классификаторов и экспериментировать с их параметрами. На этом классическом наборе данных kNN сделал очень мало ошибок.
Перевод. Оригинал здесь.
Источники
- Fix, E., Hodges, J.L. (1951); Discriminatory analysis, nonparametric discrimination: Consistency properties. Technical Report 4, USAF School of Aviation Medicine, Randolph Field, Texas.
- Mark Hall, Eibe Frank, Geoffrey Holmes, Bernhard Pfahringer, Peter Reutemann, Ian H. Witten (2009); The WEKA Data Mining Software: An Update. SIGKDD Explorations, 11(1).
- Fisher,R.A. (1936); The use of multiple measurements in taxonomic problems. Annual Eugenics, 7, Part II, 179-188.
Комментариев нет:
Отправить комментарий