Это введение в ggplot2 - это отличный пакет R для визуализации данных, которое не предполагает, что вы уже знакомы с R.
Для лучшего понимания можно посмотреть хорошо оформленную версию этой статьи в репозитории Github, которая также содержит некоторые примеры наборов данных, используемые мною, в также версию этого поста в виде кода с комментариями.
Давайте сначала посмотрим, что может ggplot2.
Набор данных "ирисы Фишера" и одна простая команда...
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species)
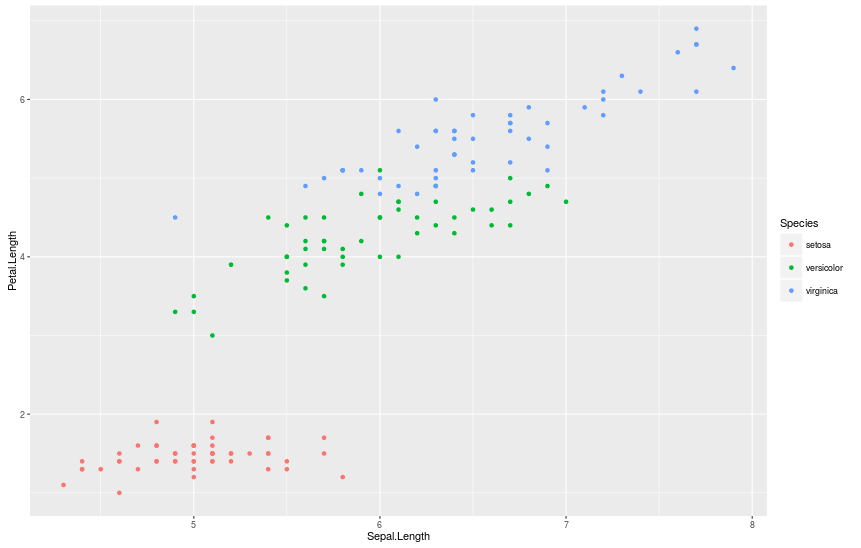
Установка
Вы можете скачать R здесь. После установки вы можете запустить R в интерактивном режиме, введя R в командной строке, или открыв стандартный GUI.
Основы R
Векторы
Векторы являются базовой структурой данных в R и создаются с помощью команды c(). Элементы вектора должны быть одинакового типа.
> numbers = c(23, 13, 5, 7, 31)
> names = c("edwin", "alice", "bob")
> names = c("edwin", "alice", "bob")
Индексы элементов начинаются с 1, доступ к элементам производится с помощью квадратных скобок.
> numbers[1]
[1] 23
> names[1]
[1] "edwin"
[1] 23
> names[1]
[1] "edwin"
Data frame
Data frame - это подобие матрицы, но с именованными столбцами, которые могут быть разных типов (как таблицы баз данных).
> books = data.frame(title = c("harry potter", "war and peace", "lord of the rings"), author = c("rowling", "tolstoy", "tolkien"), num_pages = c("350", "875", "500"))
Вы можете получать доступ к столбцам данных с помощью префикса $.
> books$title
[1] harry potter war and peace lord of the rings
Levels: harry potter lord of the rings war and peace
> books$author[1]
[1] rowling
Levels: rowling tolkien tolstoy
[1] harry potter war and peace lord of the rings
Levels: harry potter lord of the rings war and peace
> books$author[1]
[1] rowling
Levels: rowling tolkien tolstoy
Также с помощью $ вы можете создавать новые столбцы
> books$num_bought_today = c(10, 5, 8)
> books$num_bought_yesterday = c(18, 13, 20)
> books$total_num_bought = books$num_bought_today + books$num_bought_yesterday
> books$num_bought_yesterday = c(18, 13, 20)
> books$total_num_bought = books$num_bought_today + books$num_bought_yesterday
read.table
Предположим, вам необходимо экспортировать в data frame файл TSV.
Файл tsv без заголовка
Для примера возьмем файл students.tsv (со столбцами, описывающими возраст, оценку и имя каждого студента).
13 100 alice
14 95 bob
13 82 eve
Вы можете импортировать этот файл в R с помощью команды read.table().
> students = read.table("students.tsv",
+ header = F, # файл не содержит заголовка ("F" - это сокращение для "FALSE"), поэтому мы должны вручную задать имена столбцов.
+ sep = "\t", # разделители - табуляция
+ col.names = c("age", "score", "name") # имена столбцов)
+ header = F, # файл не содержит заголовка ("F" - это сокращение для "FALSE"), поэтому мы должны вручную задать имена столбцов.
+ sep = "\t", # разделители - табуляция
+ col.names = c("age", "score", "name") # имена столбцов)
Теперь мы можем обращаться к различным столбцам в data frame с помощью students$age, students$score и students$name.
Файл csv с заголовком
В качестве примера файла другого формата посмотрим studentsWithHeader.tsv.
age,score,name
13,100,alice
14,95,bob
13,82,eve
У нас те же данные, но теперь они разделены запятыми и имеют заголовок. Мы можем импортировать этот файл следующим образом:
> students = read.table("students.tsv", sep = ",",
+ header = T) # первая строка содержит имена столбцов
+ header = T) # первая строка содержит имена столбцов
Примечание: есть также функция read.csv, в которой по умолчанию sep = ",".
help
У функции read.table очень много опций. Для того, чтобы вывести их все, просто введите (read.table) (или ?read.table).
# Это работает с любыми функциями.
help(read.table)
?read.table
ggplot2
Теперь, зная основы R, можно приступить к изучению пакета ggplot2.
Установка
Одной из сильных сторон R является отличный набор пакетов на все случаи жизни. Для установки пакета используется функция install.packages().
install.packages("ggplot2")
Для загрузки пакета в текущей сессии R используется функция library().
library(ggplot2)
Построение диаграмм рассеяния с помощью функции qplot()
Давайте посмотрим, как в ggplot2 строить диаграммы рассеяния. Мы будем использовать набор данных iris, который автоматически загружается в R.
Что содержит data frame? Для того, чтобы посмотреть несколько первых строк данных, используется функция head.
> head(iris) # по умолчанию функция head выводит первые 6 строк
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> head(iris, n = 10) # мы можем явно задать, какое количество строк вывести
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> head(iris, n = 10) # мы можем явно задать, какое количество строк вывести
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
(data frame на самом деле содержит данные по трем видам ирисов: setosa, versicolor, and virginica.)
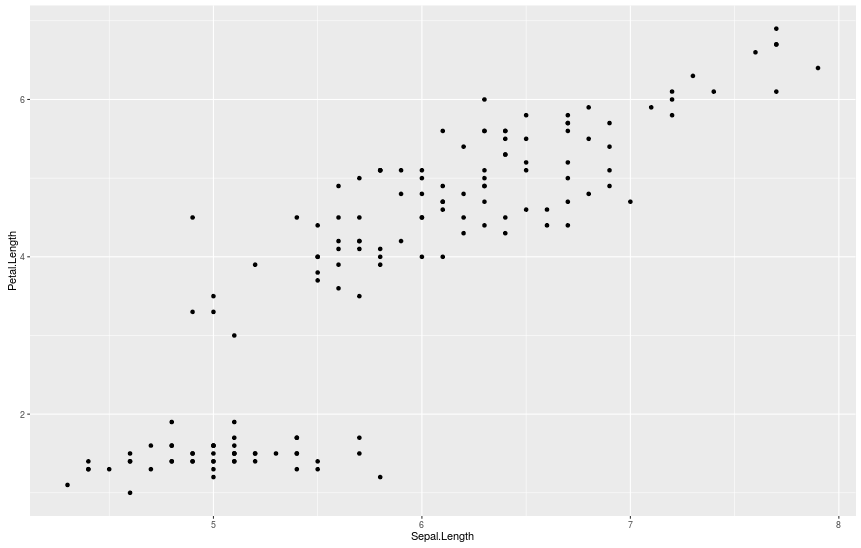
Давайте построим график Sepal.Length vs Petal.Length, используя функцию qplot() из ggplot2.
> # строим Sepal.Length vs. Petal.Length, используя данные из набора iris
> # * Первый аргумент "Sepal.Length" соответствует оси x.
> # * Второй аргумент "Petal.Length" соответствует оси y.
> # * "data = iris" означает искать данные в data frame "iris".
> qplot(Sepal.Length, Petal.Length, data = iris)
> # * Первый аргумент "Sepal.Length" соответствует оси x.
> # * Второй аргумент "Petal.Length" соответствует оси y.
> # * "data = iris" означает искать данные в data frame "iris".
> qplot(Sepal.Length, Petal.Length, data = iris)
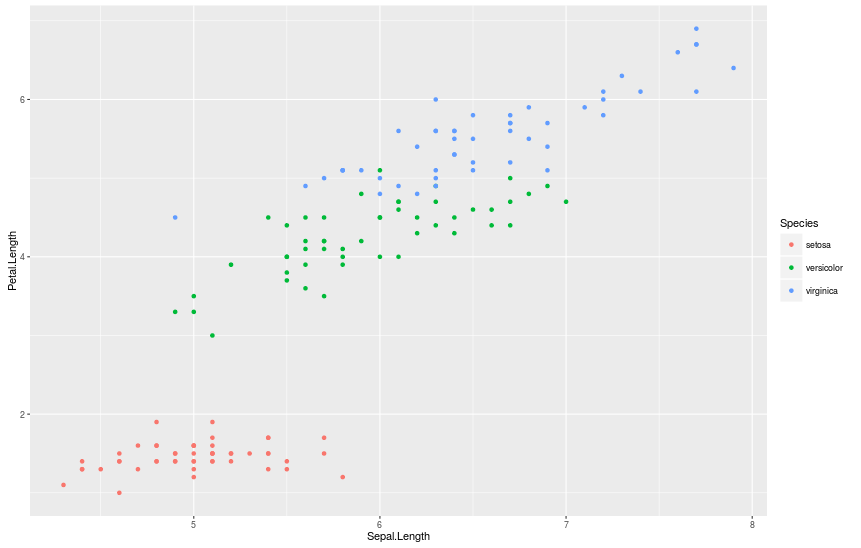
Чтобы увидеть на графике расположение каждого вида, мы можем раскрасить их, добавив аргумент color = Species.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species)
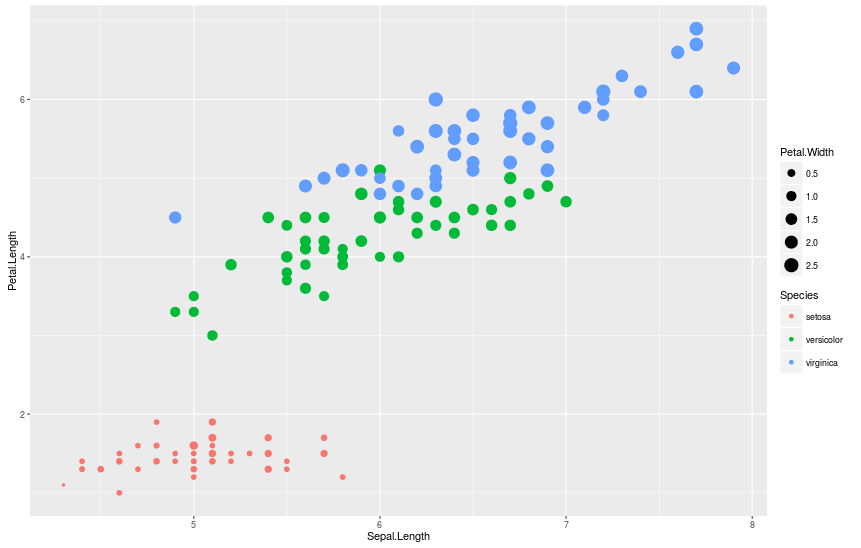
Аналогично, мы можем задать размер каждой точки в соответствии со значением, добавив аргумент size = Sepal.Width.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species, size = Petal.Width)
> # Задав значение alpha для каждой точки 0.7, мы уменьшим эффект перекрытия.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species, size = Petal.Width, alpha = I(0.7))
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species, size = Petal.Width, alpha = I(0.7))
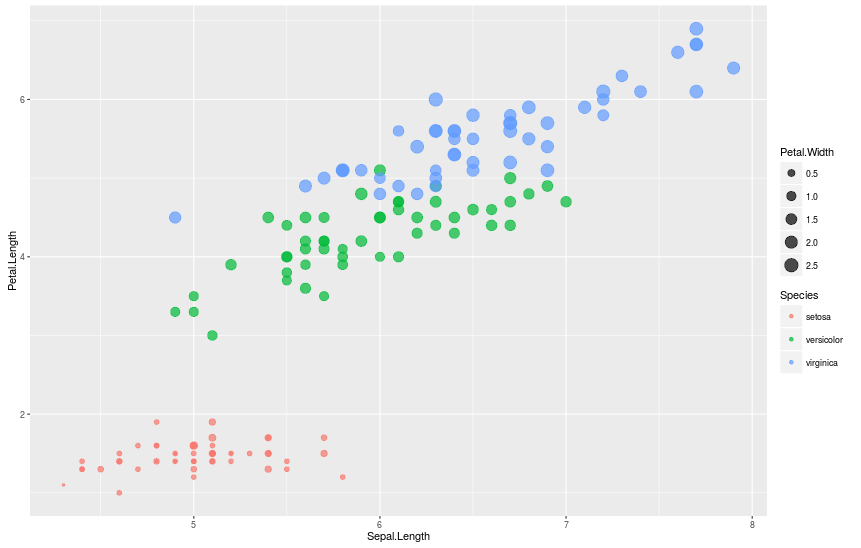
И наконец, давайте исправим подписи осей и добавим заголовок к графику.
> qplot(Sepal.Length, Petal.Length, data = iris, color = Species, xlab = "Sepal Length", ylab = "Petal Length", main = "Sepal vs. Petal Length in Fisher's Iris data")

Другие типы графиков
В приведенном выше примере мы просто задействовали тип графика, используемый по умолчанию при двух аргументах у функции qplot().
> # Эти две функции эквивалентны
> qplot(Sepal.Length, Petal.Length, data = iris, geom = "point")
> qplot(Sepal.Length, Petal.Length, data = iris)
> qplot(Sepal.Length, Petal.Length, data = iris, geom = "point")
> qplot(Sepal.Length, Petal.Length, data = iris)
Но мы также легко можем использовать другие типы графиков.
Гистограммы: geom = “bar”
> movies = data.frame(director = c("spielberg", "spielberg", "spielberg", "jackson", "jackson"), movie = c("jaws", "avatar", "schindler's list", "lotr", "king kong"), minutes = c(124, 163, 195, 600, 187))
> # Строим гистограмму количества фильмов каждого режиссера.
> qplot(director, data = movies, geom = "bar", ylab = "# movies")
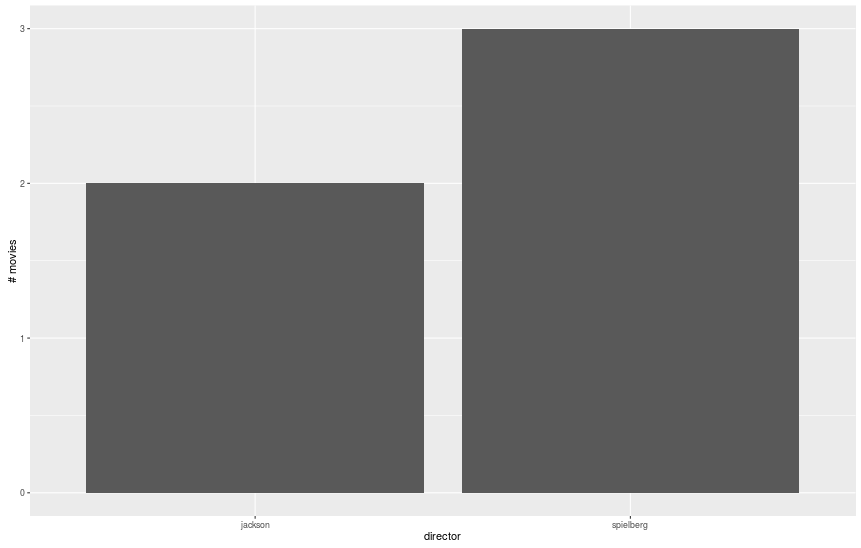
> # Здесь высота столбца равна общей продолжительности фильмов каждого режиссера.
> qplot(director, weight = minutes, data = movies, geom = "bar", ylab = "total length (min.)")
> qplot(director, weight = minutes, data = movies, geom = "bar", ylab = "total length (min.)")

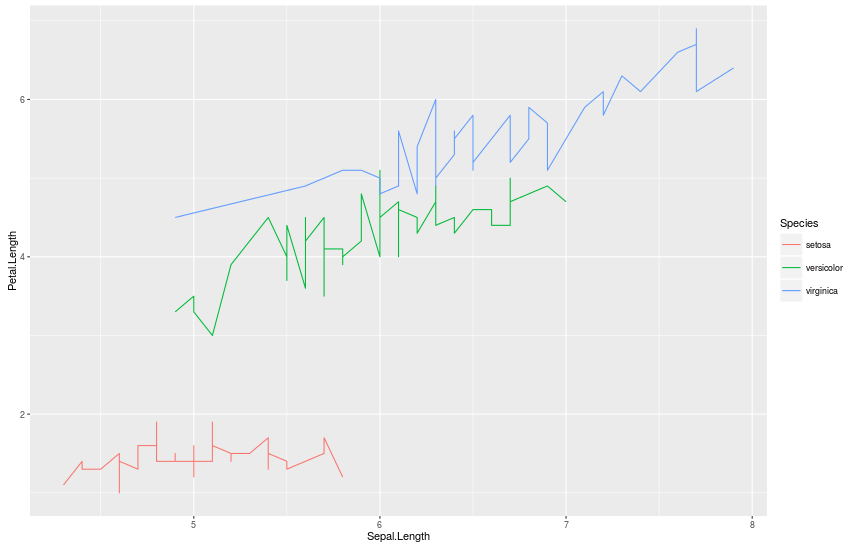
Линейные графики: geom = “line”
> qplot(Sepal.Length, Petal.Length, data = iris, geom = "line", color = Species)
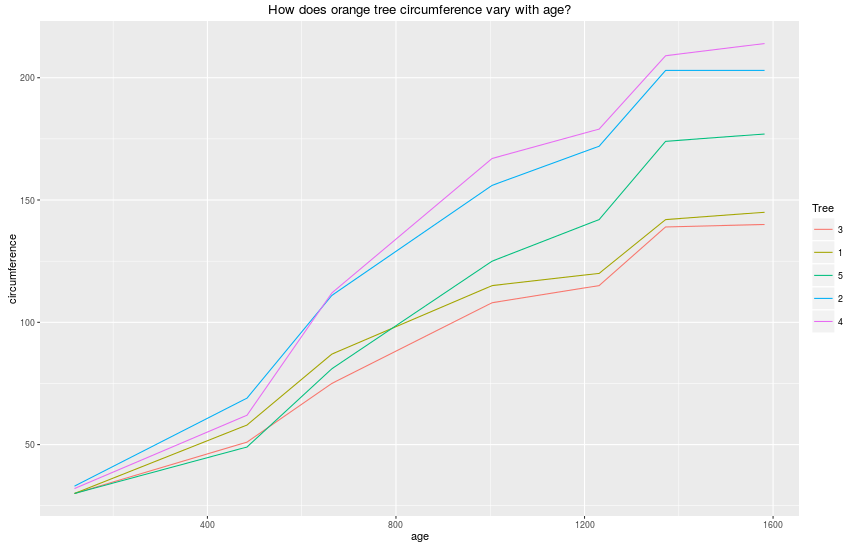
> # "Orange" - это еще один встроенный набор данных, который описывает рост апельсиновых деревьев.
> qplot(age, circumference, data = Orange, geom = "line", colour = Tree, main = "How does orange tree circumference vary with age?")
> qplot(age, circumference, data = Orange, geom = "line", colour = Tree, main = "How does orange tree circumference vary with age?")
> # Мы также можем строить графики, содержащие как точки, так и линии.
> qplot(age, circumference, data = Orange, geom = c("point", "line"), colour = Tree)
> qplot(age, circumference, data = Orange, geom = c("point", "line"), colour = Tree)
Комментариев нет:
Отправить комментарий