Перед тем, как браться за мощные и сложные методы анализа данных, полезно оценить взаимозависимости между различными переменными. Коэффициент корреляции позволяет выяснить степень и вид зависимости (прямая или обратная), а регрессия - найти уравнение, связывающее независимую и зависимую переменные.
Корреляция
Как уже говорилось выше, корреляция отражает общую взаимосвязь между движением двух переменных. Например, в случае когда одна из переменных растет, и вторая также растет, то между ними имеется положительная корреляция, в случае, если одна переменная растет, а вторая уменьшается - между ними отрицательная корреляция.
Рассмотрим простой код, позволяющий нам получить данные для расчета коэффициента корреляции:
x = sample(1:20,20)+rnorm(10,sd=2)
y = x+rnorm(10,sd=3)
z = (sample(1:20,20)/2)+rnorm(20,sd=5)
df = data.frame(x,y,z)
plot(df[,1:3])
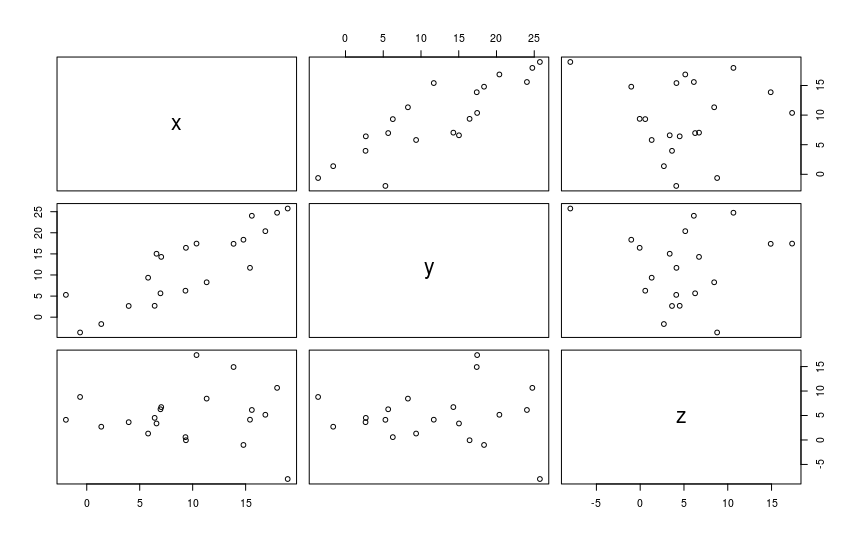
Из графика мы можем видеть, что точки формируют своего рода линию, при этом увеличению х соответствует пропорциональное увеличение y, поэтому можно предполагать, что между x и y существует положительная корреляция.
Мерой корреляции является коэффициент корреляции, который можно рассчитать разными способами. Наиболее часто используется коэффициент Пирсона, который представляет собой отношение ковариации двух переменных к сумме их вариаций, и принимает значения от 1 (подразумевает полную положительную корреляцию) до -1 (подразумевает полную отрицательную корреляцию), 0 означает полное отсутствие корреляции. Мы можем рассчитать коэффициент корреляции Пирсона с помощью функции "‘cor":
cor(df[,1:3],method="pearson")
x y z
x 1.00000000 0.85213572 -0.04933331
y 0.85213572 1.00000000 -0.02504489
z -0.04933331 -0.02504489 1.00000000
x y z
x 1.00000000 0.85213572 -0.04933331
y 0.85213572 1.00000000 -0.02504489
z -0.04933331 -0.02504489 1.00000000
cor(df[,1:3],method="spearman")
x y z
x 1.00000000 0.88120301 0.07669173
y 0.88120301 1.00000000 0.01203008
z 0.07669173 0.01203008 1.00000000
x y z
x 1.00000000 0.88120301 0.07669173
y 0.88120301 1.00000000 0.01203008
z 0.07669173 0.01203008 1.00000000
Для этих данных наши предположения о сильной положительной корреляции между x и y подтвердились, но, как принято в статистике, мы можем протестировать значимость этого коэффициента, используя параметрические допущения (коэффициент Пирсона, деленный на стандартную ошибку, должен удовлетворять t-распределению). Если эта гипотеза не подтверждается, можно использовать ранговый коэффициент корреляции Спирмена.
cor.test(df$x,df$y,method="pearson")
Pearson's product-moment correlation
data: df$x and df$y
t = 6.9084, df = 18, p-value = 1.852e-06
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.6575805 0.9401409
sample estimates:
cor
0.8521357
Pearson's product-moment correlation
data: df$x and df$y
t = 6.9084, df = 18, p-value = 1.852e-06
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.6575805 0.9401409
sample estimates:
cor
0.8521357
cor.test(df$x,df$y,method="spearman")
Spearman's rank correlation rho
data: df$x and df$y
S = 158, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.881203
Spearman's rank correlation rho
data: df$x and df$y
S = 158, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.881203
При возведении коэффициента корреляции Пирсона в квадрат мы получаем долю вариации y, объясняемую вариацией x (для рангового коэффициента Спирмена это не так, его квадрат не имеет статистической значимости). В нашем случае около 75% вариации y объясняется вариацией x.
Однако эти результаты не позволяют говорить о точном объяснении влияния x на y, так как x может влиять на y различными способами, не только напрямую. Все, что мы можем сказать, исходя из значения коэффициента корреляции - это то, что эти две переменные как-то связаны друг с другом. Для того, чтобы выяснить, каким образом x влияет на y, необходимо использовать методы регрессии.
Линейная регрессия:
Регрессия отличается от корреляции тем, что она пытается найти взаимосвязь между переменными в виде уравнения, например для случая самой простой линейной регрессии это уравнение вида Y=aX+b. Поскольку с помощью уравнений мы часто пытаемся описать природные процессы, такие уравнения чаще всего дают только приближенную модель описания реальности, поэтому линейную регрессию часто называют линейным моделированием.
В R мы можем построить и протестировать значимость линейных моделей.
m1 = lm(mpg~cyl,data=mtcars)
summary(m1)
<-lm cyl="" data="mtcars)</span" mpg="">Call:
lm(formula = mpg ~ cyl, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.9814 -2.1185 0.2217 1.0717 7.5186
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.8846 2.0738 18.27 < 2e-16 ***
cyl -2.8758 0.3224 -8.92 6.11e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.206 on 30 degrees of freedom
Multiple R-squared: 0.7262, Adjusted R-squared: 0.7171
F-statistic: 79.56 on 1 and 30 DF, p-value: 6.113e-10
lm(formula = mpg ~ cyl, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.9814 -2.1185 0.2217 1.0717 7.5186
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.8846 2.0738 18.27 < 2e-16 ***
cyl -2.8758 0.3224 -8.92 6.11e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.206 on 30 degrees of freedom
Multiple R-squared: 0.7262, Adjusted R-squared: 0.7171
F-statistic: 79.56 on 1 and 30 DF, p-value: 6.113e-10
Базовой функцией в R для построения линейной регрессии является "lm". Ей передается в формула в виде y~x и опционально аргумент data.
Используя функцию "summary", мы можем получить всю информацию о нашей модели: формула, распределение остатков (ошибка нашей модели), значение коэффициента и его значимость плюс информация о достоверности модели в целом в виде коэффициента детерминации R2 (0,71 в нашем случае), который представляет долю вариации y, объясняемую x, то есть 71% вариации в mpg можно объяснить вариацией cyl.
Перед тем, как кричать "Эврика!", необходимо убедиться, что допущения модели выполняются. Действительно, линейные модели налагают некоторые ограничения на ваши данные, первым из которых является требование, что ваши данные должны быть нормально распределены, вторым - дисперсия должна быть гомогенной для всех значений x (иногда это требование называется homoscedaticity), третьим - независимость значений, то есть значение y при заданном значении x не должно влиять на другие значения y.
Есть прекрасная встроенная функция для проверки всех этих требований:
par(mfrow=c(2,2))
plot(m1)
plot(m1)
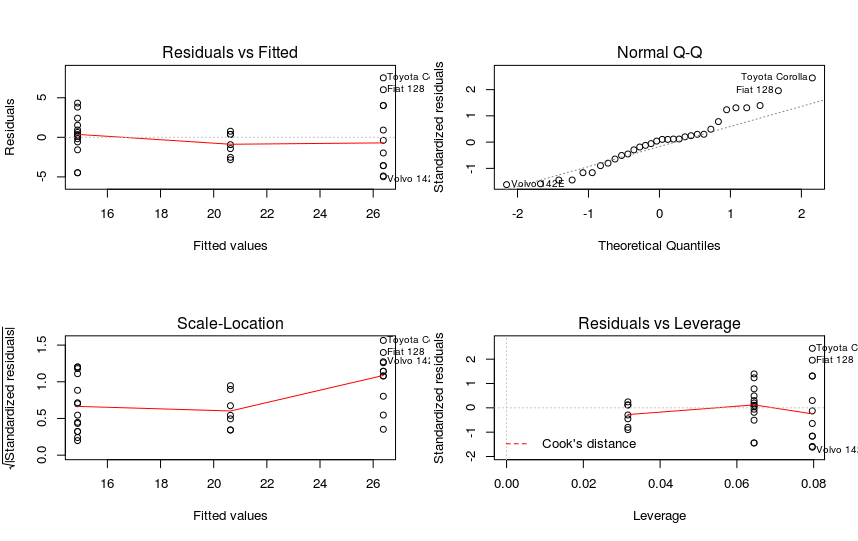
Аргумент "par" используется для того, чтобы вывести все графики в одном окне.
Графики в первых столбцах среди прочего позволяют оценить гомогенность дисперсии. Мы не должны видеть никакого паттерна, точки должны распределяться случайным образом. В нашем случае это не так.
Для записи графика в верхнем правом углу проверяется допущение о нормальном распределении. Если ваши данные распределены нормально, точки должны более менее точно ложиться на прямую, в этом случае данные нормальны.
Последний график показывает, как каждое значение y влияет на модель, каждая точка поочередно удаляется, и новая модель сравнивается с той, где эта точка была. Если точка сильно влияет на модель, она представляет собой выброс. Такие точки должны удаляться из набора данных, чтобы исключить их чрезмерное влияние на модель.
Преобразование данных
К данным, которые не соответствуют нормальному распределению, или гетерогенных данным, могут применяться несколько математических преобразований.
mtcars$Mmpg = log(mtcars$mpg)
plot(Mmpg~cyl,mtcars)
В нашем случае все выглядит нормально, но мы все еще можем удалить два выброса в категории 8 "cyl".
n = rownames(mtcars)[mtcars$Mmpg!=min(mtcars$Mmpg[mtcars$cyl==8])]
mtcars2 = subset(mtcars,rownames(mtcars)%in%n)
Первая строка запрашивает имена строк в "mtcars" (rownames(mtcars)), но возвращает только те, где значение переменной "mpg" не равно (!=) минимальному значению переменной "Mmpg", которая попадает в категорию 8 цилиндров. Тогда список "n" включает все эти имена строк и далее создается новый data frame, который содержит только строки с именами, представленными в "n".
На этой стадии преобразования данных и удаления выбросов лучше всего использовать графики, чтобы визуально оценивать свои действия.
Теперь давайте вернемся к нашей модели линейной регрессии с новым набором данных.
model = lm(Mmpg~cyl,mtcars2)
summary(model)
Call:
<-lm cyl="" mpg="" mtcars2="" span="">lm(formula = Mmpg ~ cyl, data = mtcars2)
Residuals:
Min 1Q Median 3Q Max
-0.19859 -0.08576 -0.01887 0.05354 0.26143
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.77183 0.08328 45.292 < 2e-16 ***
cyl -0.12746 0.01319 -9.664 2.04e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.1264 on 28 degrees of freedom
Multiple R-squared: 0.7693, Adjusted R-squared: 0.7611
F-statistic: 93.39 on 1 and 28 DF, p-value: 2.036e-10
Residuals:
Min 1Q Median 3Q Max
-0.19859 -0.08576 -0.01887 0.05354 0.26143
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.77183 0.08328 45.292 < 2e-16 ***
cyl -0.12746 0.01319 -9.664 2.04e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.1264 on 28 degrees of freedom
Multiple R-squared: 0.7693, Adjusted R-squared: 0.7611
F-statistic: 93.39 on 1 and 28 DF, p-value: 2.036e-10
plot(model)
Снова у нас сильно значимые пересечение и угол наклона, модель объясняет 76% вариации log(mpg) и в целом значима. Теперь нам нужна таблица ANOVA, в R ее можно создать несколькими способами (как всегда, есть простой способ, и более сложный, но с возможностью настройки).
anova(model)
Analysis of Variance Table
Response: Mmpg
Df Sum Sq Mean Sq F value Pr(>F)
cyl 1 1.49252 1.49252 93.393 2.036e-10 ***
Residuals 28 0.44747 0.01598
Analysis of Variance Table
Response: Mmpg
Df Sum Sq Mean Sq F value Pr(>F)
cyl 1 1.49252 1.49252 93.393 2.036e-10 ***
Residuals 28 0.44747 0.01598
library(car)
Le chargement a nécessité le package : MASS
Le chargement a nécessité le package : nnet
Anova(model)
Anova Table (Type II tests)
Response: Mmpg
Sum Sq Df F value Pr(>F)
cyl 1.49252 1 93.393 2.036e-10 ***
Residuals 0.44747 28
Anova Table (Type II tests)
Response: Mmpg
Sum Sq Df F value Pr(>F)
cyl 1.49252 1 93.393 2.036e-10 ***
Residuals 0.44747 28
Вторая функция ("Anova") позволяет вам задать, какой тип суммы квадратов вы хотите рассчитать (здесь хорошее объяснение различных подходов), а также произвести коррекцию с учетом гетерогенности вариации.
Anova(model,white.adjust=TRUE)
Analysis of Deviance Table (Type II tests)
Response: Mmpg
Df F Pr(>F)
cyl 1 69.328 4.649e-09 ***
Residuals 28
Analysis of Deviance Table (Type II tests)
Response: Mmpg
Df F Pr(>F)
cyl 1 69.328 4.649e-09 ***
Residuals 28
Вы можете заметить, что p-value получилось немного больше. Эта функция очень полезна для несбалансированного набора данных (как в нашем случае), но необходимо соблюдать осторожность при выборе модели, особенно если переменных - предикторов несколько, так как сумма квадратов type II подразумевает, что взаимосвязи между предикторами нет.
Суммируя все вышеприведенное, можно сказать, что корреляция является хорошим первым шагом в исследовании данных, перед выполнением более серьезного анализа, и хорошим способом выбрать представляющие интерес переменные. Следующим шагом является создание модели взаимосвязи между переменными, и самой простой моделью является линейная регрессия, которая позволяет найти уравнение, связывающее переменные, и протестировать модель с помощью функций summary и anova.
Комментариев нет:
Отправить комментарий