Перевод.
Оригинал здесь.
В
этой статье я покажу вам применение
алгоритма kNN (k - ближайших соседей) с
использованием программирования на R.
Мы
также рассмотрим пример, в котором
описывается поэтапно процесс использования
kNN для построения модели.
Этот
алгоритм является алгоритмом с учителем,
где известна цель, но неизвестна
траектория движения к ней. Понимание
алгоритма ближайших соседей составляет
квинтэссенцию машинного обучения.
Подобно регрессии, этот алгоритм легко
изучать и применять.
Что
такое алгоритм kNN?
Предположим,
у нас есть несколько групп маркированных
образцов. Элементы, присутствующие в
группах, являются по своей природе
однородными. Теперь предположим, что у
нас есть немаркированный пример, который
нужно отнести к одной из нескольких
маркированных групп. Как ты это делаешь?
Как правило, используя kNN-алгоритм.
k
ближайших соседей - простой алгоритм,
который хранит все доступные данные и
классифицирует новые данные большинством
голосов его k соседей. Такой алгоритм
разделяет немаркированные точки данных
на четко определенные группы.
Как
выбрать подходящее значение k?
Выбор
количества ближайших соседей, т. е.
определение значения k, играет значительную
роль в эффективности модели. То есть,
выбор k определит, насколько хорошо
данные подходят для обобщения результатов
алгоритма kNN. Большое значение k дает
преимущество, которое заключается в
уменьшении дисперсии для шумных данных;
при этом наблюдается побочный эффект
смещения, из-за которого обучаемый
алгоритм стремится игнорировать более
мелкие паттерны, которые могут нести
полезную информацию.
В
приведенном ниже примере мы на практике
рассмотрим выбор подходящего значения
k.
Пример
алгоритма kNN
Давайте
рассмотрим 10 напитков, которые оцениваются
по двум параметрам по шкале от 1 до 10.
Этими параметрами являются «сладость»
и «газированность». Это оценка, скорее
основанная на восприятии, и поэтому
может отличаться у каждого человека.
Оценки нескольких напитков выглядят
так:

«Сладость»
определяет восприятие содержания сахара
в напитках. «Газированность» обнаруживает
наличие пузырьков в напитке из-за
содержания углекислого газа. Опять же,
все эти рейтинги основаны на личном
восприятии и являются относительными.

Из
приведенного выше рисунка ясно, что мы
разделили 10 напитков на 4 группы, а
именно: «COLD DRINKS», «ENERGY DRINKS», «HEALTH DRINKS» и
«HARD DRINKS». Вопрос здесь в том, к какой
группе отнести напиток «Maaza»? Это можно
определить путем вычисления расстояния.
Вычисление
расстояния
Теперь
рассчитаем расстояния между «Maaza» и его
ближайшими соседями («ACTIV», «Vodka», «Pepsi»
и «Monster»). Для этого нам нужно выбрать
формулу расчета расстояния, наиболее
популярной из является евклидово
расстояние, т.е. кратчайшее расстояние
между 2 точками, которые может быть
получено с помощью линейки.

Используя
координаты Maaza (8,2) и Vodka (2,1), расстояние
между «Maaza» и «Vodka» можно рассчитать
как:
dist(Maaza,Vodka)
= 6.08

Используя
евклидово расстояние, мы можем рассчитать
расстояние от Maaza до каждого из ближайших
соседей. Расстояние между Maaza и ACTIV
является наименьшей, можно предположить,
что Maaza такой же природы, как ACTIV, который,
в свою очередь, относится к группе
напитков (Health Drinks).
Если
k = 1, алгоритм рассматривает самого
ближайшего соседа к Maaza, т.е. ACTIV; если k
= 3, алгоритм сравнивает расстояния от
3 ближайших соседей до Maaza (ACTIV, Vodka,
Monster) - ближе всего к Maaza стоит ACTIV.
Преимущества
и недостатки алгоритма kNN
Преимущества:
алгоритм имеет беспристрастный характер
и не делает предварительных предположений
о данных. Будучи простым и эффективным,
он легко реализуем и приобрел большую
популярность.
Недостатки:
данный метод не создает каких-либо
моделей или правил, обобщающих предыдущий
опыт, - в выборе решения они основываются
на всем массиве доступных исторических
данных, поэтому невозможно сказать, на
каком основании строятся ответы. При
использовании метода возникает
необходимость полного перебора обучающей
выборки при распознавании, следствие
этого -вычислительная трудоемкость.
Пример:
диагностика рака простаты
Машинное
обучение находит широкое применение в
фармацевтической промышленности,
особенно для выявления роста онкогенных
(раковых) клеток. R применяется в машинном
обучении для построения моделей
прогнозирования аномального роста
клеток, тем самым помогая выявлять рак.
Давайте
посмотрим на процесс построения этой
модели с использованием алгоритма kNN в
R. Ниже вы увидите, что я объясняю каждую
строку кода, написанную для выполнения
этой задачи.
Этап
1- сбор данных
Мы
будем использовать набор данных для
100 пациентов (созданных исключительно
для примера) для реализации алгоритма
knn и интерпретации результатов. Набор
данных был подготовлен с учетом
результатов, которые обычно получают
из DRE (Digital Rectal Exam). Вы можете загрузить
набор
данных и повторить этот пример.
Набор
данных состоит из 100 наблюдений и 10
переменных (из которых 8 переменных
числовых и одна категориальная, а также
ID):
-
радиус
-
текстура
-
периметр
-
гладкость
-
компактность
-
симметричность
-
фрактальная размерность
В
реальной жизни для измерения вероятности
развития рака используются десятки
важных параметров, но для простоты мы
рассмотрим только 8 из них.
Вот
как выглядит набор данных:

Этап
2- подготовка и исследование данных

Давайте
сначала разберем наш код, прежде чем
переходить к следующему этапу:
setwd("C:/Users/Payal/Desktop/KNN") #Using this command, we've imported the ‘Prostate_Cancer.csv’ data file. This command is used to point to the folder containing the required file. Do keep in mind, that it’s a common mistake to use “\” instead of “/” after the setwd command.prc <- read.csv("Prostate_Cancer.csv",stringsAsFactors = FALSE) #This command imports the required data set and saves it to the prc data frame.stringsAsFactors = FALSE #This command helps to convert every character vector to a factor wherever it makes sense.str(prc) #We use this command to see whether the data is structured or not.
Мы
видим, что данные структурированы в 10
переменных и 100 наблюдений. Первая
переменная «id» может быть удалена, так
как она не предоставляет полезную
информацию.

prc <- prc[-1] #removes the first variable(id) from the data set.
Набор
данных содержит пациентов, у которых
были диагностированы злокачественные
(M) или доброкачественные (B) опухоли.
table(prc$diagnosis_result) # it helps us to get the numbers of patients
(diagnost_result
- наша целевая переменная, то есть эта
переменная будет определять результаты
диагноза на основе 8 числовых переменных)
Если
мы хотим переименовать B как «Benign»
(доброкачественные) и M как «Malignant»
(злокачественные) и увидеть результаты
в процентной форме, мы можем написать:
rc$diagnosis <- factor(prc$diagnosis_result, levels = c("B", "M"), labels = c("Benign", "Malignant"))round(prop.table(table(prc$diagnosis)) * 100, digits = 1) # it gives the result in the percentage form rounded of to 1 decimal place( and so it’s digits = 1)

Нормализация
численных данных
Этот
этап имеет первостепенное значение,
поскольку масштаб, используемый для
значений для каждой переменной, может
отличаться. Лучшей практикой является
нормализация данных и преобразование
всех значений в общий масштаб.
normalize <- function(x) {
return ((x - min(x)) / (max(x) - min(x))) }
Мы
запускаем этот код, когда нам нужно
нормализовать числовые признаки в
наборе данных. Вместо нормализации
каждой из 8 отдельных переменных мы
делаем все сразу:
prc_n <- as.data.frame(lapply(prc[2:9], normalize))
Первой
переменной в нашем наборе данных (после
удаления id) является «diagn_result», которая
не числовая по своей природе. Поэтому
мы начинаем со второй переменной. Функция
lapply () применяет normalize () к каждому признаку
во фрейме данных. Конечный результат с
помощью функции as.data.frame () сохраняется
в data frame prc_n.
Давайте
проверим на переменной «radius», были ли
данные нормализованы.
summary(prc_n$radius)
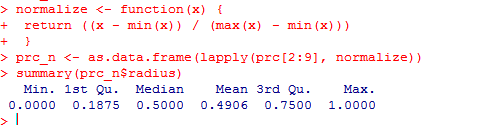
Результаты
показывают, что данные были нормализованы.
Попробуйте другие переменные, такие
как perimeter, area и т.д.
Создание
обучающего и тестового наборов данных
Алгоритм
kNN применяется к обучающему набору
данных, и затем результаты проверяются
на тестовом наборе.
Для
этого мы разделим набор данных на 2 части
в соотношении 65: 35 для обучающего и
тестового набора данных соответственно.
Вы можете использовать другое соотношение
в зависимости от ваших требований.
Мы
разделим data frame prc_n на prc_train и prc_test.
prc_train <- prc_n[1:65,] prc_test <- prc_n[66:100,]
Пустые
значения в каждой из приведенных выше
команд указывают, что должны быть
включены все строки и столбцы .
Наша
целевая переменная - «diagn_result».
prc_train_labels <- prc[1:65, 1]
prc_test_labels <- prc[66:100, 1] #This code takes the diagnosis factor in column 1 of the prc data frame and on turn creates prc_train_labels and prc_test_labels data frame.
Этап
3 – Обучение модели
Для
обучения модели используется функция
knn (), для этого нам необходимо установить
пакет «class». Функция knn () идентифицирует
k-ближайших соседей, используя эвклидово
расстояние, где k - заданное пользователем
число.
Для
этого вам нужно ввести следующие команды:
install.packages(“class”) library(class)
Теперь
мы готовы использовать функцию knn() для
классификации тестовых данных.
prc_test_pred <- knn(train = prc_train, test = prc_test,cl = prc_train_labels, k=10)
Значение
k обычно выбирается как квадратный
корень из числа наблюдений.
knn()
возвращает значение коэффициента для
прогнозируемых столбцов для каждого
из примеров в наборе тестовых данных,
которое затем присваивается prc_test_pred

Этап
4 – оценка эффективности модели
Мы
построили модель, но нам также нужно
проверить точность предсказанных
значений в prc_test_pred, соответствуют ли
они известным значениям в prc_test_labels. Для
этого нам нужна функция CrossTable () из пакета
gmodels.
Мы
можем установить этот пакет с помощью
следующей команды:
install.packages("gmodels")Далее проверяем точность предсказанных значений:


Тестовые
данные состояли из 35 наблюдений. Из них
7 случаев были точно предсказаны (TN->
True Negatives) как Benign (B), что составляет 20%.
Кроме того, 15 из 35 наблюдений были точно
предсказаны (TP-> True Positives) как Malignant (M),
что составляет 42,8%.
Был
один случай False Negatives (FN), когда на самом
деле опухоль была злокачественной по
своей природе, но была предсказана как
доброкачественная.
Было
12 случаев ложных положительных результатов
(FP), что означает, что 12 случаев были
фактически доброкачественными по своей
природе, но были предсказаны как
злокачественные.
Общая
точность модели составляет 62,8% ((TN + TP) /
35), таким образом, могут быть шансы
улучшить ее эффективность.
Этап
5 – улучшение эффективности модели
Это
можно сделать, повторив шаги 3 и 4 с
другими значениями k. Как правило, в
качестве k берется квадратный корень
числа наблюдений, и в нашем случае мы
взяли k = 10. Для повышения точности
прогнозирования значение k можно менять
в определенном диапазоне. Попробуйте
сделать это со значениями по вашему
выбору. Также помните, что необходимо
сохранять минимально возможное значение
FN.
Комментариев нет:
Отправить комментарий