Ранее мы исследовали возможность применения наивного байесовского классификатора для предсказания движения котировок акций. Хотя наивный Байес - это очень мощный алгоритм, он имеет тенденцию быть "черным ящиком", то есть трудно понять, что происходит внутри во время его работы. Кроме того, для использования его в трейдинге вы должны иметь возможность снабжать его котировками в режиме реального времени и одновременно делать прогнозы и открывать позиции.
Нам нужна возможность сначала выработать стратегию, используя возможности нашего наивного байесовского классификатора, а затем применять ее в торговле.
Ответ можно получить от менее известного, но хорошо исследованного метода data mining, известного как анализ ассоциативных правил.
В этой публикации мы коротко рассмотрим концепции, лежащие в основе анализа ассоциативных правил, и используем его для построения базовой стратегии трейдинга на паре USD/CAD.
Что такое анализ ассоциативных правил?
Анализ ассоциативных правил - это один из шести методов data mining. В двух словах его можно определить как технику поиска ассоциаций между переменными. Он использует различные алгоритмы для построения операторов “ if... then….”, с высокой достоверностью описывающих отношения между переменными в ваших данных. Классическим примером является размещение товаров на полках в супермаркете. Проводится анализ данных о покупках и находят взаимосвязи между покупаемыми товарами типа: "если человек покупает молоко и яйца, то он с большой вероятностью купит также хлеб". Это позволяет менеджерам размещать эти продукты рядом, что облегчает жизнь покупателям и увеличивает объем продаж.
Для анализа ассоциативных правил разработано несколько популярных алгоритмов, например Apriori, который используется для поиска в больших базах данных объектов, которые с большой вероятностью связаны ассоциативными правилами. Так как количество потенциальных "объектов", или в нашем случае "индикаторов", может быть очень большим, мы будем использовать предопределенный набор технических индикаторов и алгоритм, с которым мы уже знакомы, для построения набора правил, который мы затем сможем использовать в торговле.
Построение стратегии с использованием анализа ассоциативных правил
Теперь давайте посмотрим, как мы можем использовать анализ ассоциативных правил для получения набора четких и понятных правил, которые мы сможем применить для построения своей стратегии торговли.
Для начала скачаем нужные нам данные: 4-часовой график SD/CAD с 23 октября 2011 года по 22 сентября 2014 года (скачать можно здесь).
Затем установим требуемые пакеты:
> # содержит необходимые технические индикаторы
> install.packages("quantmod")
> library(quantmod)
> # содержит наивный байесовский классификатор
> install.packages("e1071")
> library(e1071)
> #содержит функции для визуализации данных
> install.packages("ggplot2")
> library(ggplot2)
> install.packages("quantmod")
> library(quantmod)
> # содержит наивный байесовский классификатор
> install.packages("e1071")
> library(e1071)
> #содержит функции для визуализации данных
> install.packages("ggplot2")
> library(ggplot2)
И рассчитываем наши индикаторы:
> # наш набор данных
> Data<-read.csv("USDCAD.csv")
> #20-периодный индекс товарного канала (CCI) для High/Low/Close
> CCI20<-CCI(Data[,3:5],n=20)
> Data<-read.csv("USDCAD.csv")
> #20-периодный индекс товарного канала (CCI) для High/Low/Close
> CCI20<-CCI(Data[,3:5],n=20)
Замечание: так как CCI рассчитывается от закрытия, мы будем рассчитывать другие наши индикаторы также от закрытия и сдвигать их значения на один бар назад.
> #3-периодный RSI по ценам закрытия
> RSI3<-RSI(Cl(Data),n=3)
> #10-периодная двойная экспоненциальная скользящая средняя (DEMA) со стандартными параметрами. И мы смотрим на разницу цены и DEMA.
> DEMA10<-DEMA(Cl(Data),n = 10, v = 1, wilder = FALSE)
> DEMA10c<-Cl(Data) - DEMA10
> #Преобразуем в пипсы
> DEMA10c<-DEMA10c/.0001
> RSI3<-RSI(Cl(Data),n=3)
> #10-периодная двойная экспоненциальная скользящая средняя (DEMA) со стандартными параметрами. И мы смотрим на разницу цены и DEMA.
> DEMA10<-DEMA(Cl(Data),n = 10, v = 1, wilder = FALSE)
> DEMA10c<-Cl(Data) - DEMA10
> #Преобразуем в пипсы
> DEMA10c<-DEMA10c/.0001
Затем создаем наш набор данных, округляем значения индикатора и сдвигаем значения:
> #удаление самой последней точки данных из вычислений и сдвига данных по направлению этого бара позволяет предотвратить доступ к информации, которой мы не могли знать на момент расчета.
> Indicators<-data.frame(RSI3,DEMA10c,CCI20)
> Indicators<-round(Indicators,2)
> Indicators<-Indicators[-nrow(Data),]
> Indicators<-data.frame(RSI3,DEMA10c,CCI20)
> Indicators<-round(Indicators,2)
> Indicators<-Indicators[-nrow(Data),]
Далее, рассчитываем переменную, которую мы хотим спрогнозировать, направление следующего бара, и создаем наш финальный набор данных.
> Price<-Cl(Data)-Op(Data)
> Class<-ifelse(Price > 0 ,"UP","DOWN")
> # удаляем самую старую точку данных, чтобы наш Class соответствовал индикаторам
> Class<-Class[-1]
> DataSet<-data.frame(Indicators,Class)
> # удаляем экземпляры, в которых еще нет рассчитанных индикаторов
> DataSet<-DataSet[-c(1:19),]
> #Разделяем на обучающую выборку (60% данных), тестовую выборку (20% данных) и выборку для валидации (20% данных)
> Training<-DataSet[1:2760,];Test<-DataSet[2761:3680,];Validation<-DataSet[3681:4600,]
> Class<-ifelse(Price > 0 ,"UP","DOWN")
> # удаляем самую старую точку данных, чтобы наш Class соответствовал индикаторам
> Class<-Class[-1]
> DataSet<-data.frame(Indicators,Class)
> # удаляем экземпляры, в которых еще нет рассчитанных индикаторов
> DataSet<-DataSet[-c(1:19),]
> #Разделяем на обучающую выборку (60% данных), тестовую выборку (20% данных) и выборку для валидации (20% данных)
> Training<-DataSet[1:2760,];Test<-DataSet[2761:3680,];Validation<-DataSet[3681:4600,]
И наконец строим наш наивный байесовский классификатор:
> # используем наши три технических индикатора для предсказания класса в обучающей выборке
> NB<-naiveBayes(Class ~ RSI3 + CCI20 + DEMA10c, data=Training)
> NB<-naiveBayes(Class ~ RSI3 + CCI20 + DEMA10c, data=Training)
Давайте посмотрим, насколько хорошо алгоритм работает сам по себе, чтобы понять, от чего отталкиваться.
> table(predict(NB,Test,type="class"),Test[,4],dnn=list('predicted','actual'))
actual
predicted DOWN UP
DOWN 259 266
UP 176 219
actual
predicted DOWN UP
DOWN 259 266
UP 176 219
Около 52%, неплохо, но давайте посмотрим, сможем ли мы улучшить результат.
> # получам список всех наших предсказаний
> TestPredictions<-predict(NB,Test,type="class")
> #Смотрим, корректны ли они
> TestCorrect<-ifelse(TestPredictions==Test[,4],"Correct","Incorrect")
> #строим один общий набор данных, который мы можем использовать для всех графиков
> TestData<-data.frame(Test,TestPredictions,TestCorrect)
> TestPredictions<-predict(NB,Test,type="class")
> #Смотрим, корректны ли они
> TestCorrect<-ifelse(TestPredictions==Test[,4],"Correct","Incorrect")
> #строим один общий набор данных, который мы можем использовать для всех графиков
> TestData<-data.frame(Test,TestPredictions,TestCorrect)
Хорошо, давайте посмотрим, какие паттерны смог найти наш алгоритм на обучающей выборке и насколько хорошо они подходят к тестовой выборке.
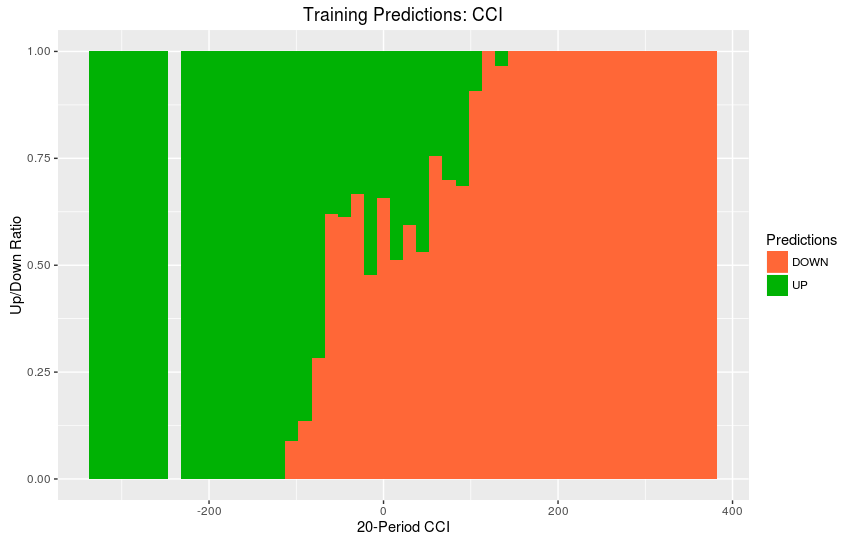
>ggplot(TestData,aes(x=CCI20,fill=TestPredictions))+geom_histogram(binwidth=15,position="fill")+labs(title="Training Predictions: CCI", x = "20-Period CCI", y= "Up/Down Ratio",fill="Predictions")+scale_fill_manual(values=c("#FF6737","#00B204"))
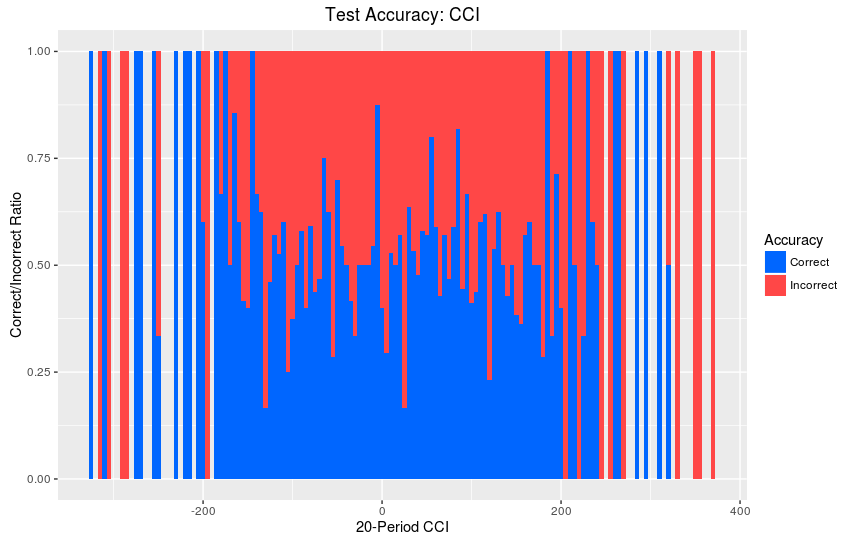
>ggplot(TestData,aes(x=CCI20,fill=TestCorrect))+geom_histogram(binwidth=5,position="fill")+labs(title="Test Accuracy: CCI", x = "20-Period CCI", y= "Correct/Incorrect Ratio",fill="Accuracy")+scale_fill_manual(values=c("#0066FF","#FF4747"))
>ggplot(TestData,aes(x=CCI20,fill=TestCorrect))+geom_histogram(binwidth=5,position="fill")+labs(title="Test Accuracy: CCI", x = "20-Period CCI", y= "Correct/Incorrect Ratio",fill="Accuracy")+scale_fill_manual(values=c("#0066FF","#FF4747"))
>ggplot(TestData,aes(x=RSI3,fill=TestPredictions))+geom_histogram(binwidth=15,position="fill")+labs(title="Training Predictions: RSI", x = "3-Period RSI", y= "Up/Down Ratio",fill="Predictions")+scale_fill_manual(values=c("#FF6737","#00B204"))
>ggplot(TestData,aes(x=RSI3,fill=TestCorrect))+geom_histogram(binwidth=5,position="fill")+labs(title="Test Accuracy: RSI", x = "3-Period RSI", y= "Correct/Incorrect Ratio",fill="Accuracy")+scale_fill_manual(values=c("#0066FF","#FF4747"))
>ggplot(TestData,aes(x=RSI3,fill=TestCorrect))+geom_histogram(binwidth=5,position="fill")+labs(title="Test Accuracy: RSI", x = "3-Period RSI", y= "Correct/Incorrect Ratio",fill="Accuracy")+scale_fill_manual(values=c("#0066FF","#FF4747"))


>ggplot(TestData,aes(x=DEMA10c,fill=TestPredictions))+geom_histogram(binwidth=15,position="fill")+labs(title="Training Predictions: DEMA", x = "10-Period DEMA", y= "Up/Down Ratio",fill="Predictions")+scale_fill_manual(values=c("#FF6737","#00B204"))
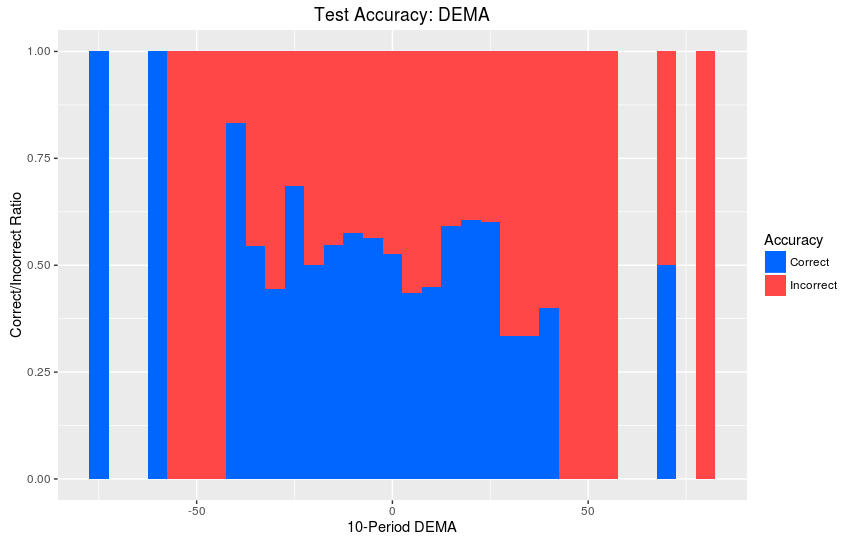
>ggplot(TestData,aes(x=DEMA10c,fill=TestCorrect))+geom_histogram(binwidth=5,position="fill")+labs(title="Test Accuracy: DEMA", x = "10-Period DEMA", y= "Correct/Incorrect Ratio",fill="Accuracy")+scale_fill_manual(values=c("#0066FF","#FF4747"))
>ggplot(TestData,aes(x=DEMA10c,fill=TestCorrect))+geom_histogram(binwidth=5,position="fill")+labs(title="Test Accuracy: DEMA", x = "10-Period DEMA", y= "Correct/Incorrect Ratio",fill="Accuracy")+scale_fill_manual(values=c("#0066FF","#FF4747"))

Графики “Predictions over Training Set” показывают, где во всем диапазоне значений нашего индикатора (ось x) байесовский алгоритм спрогнозировал лонги, а где шоты. Зеленым показана область, где алгоритм предсказывает лонги, а оранжевым - шоты.
Графики “Accuracy over Test Set” показывают, где алгоритм наиболее точен для того же индикатора на тестовой выборке. Синим показаны корректные предсказания алгоритма, красным - некорректные. Это показывает нам, где найденные паттерны остются верными за пределами обучающей выборки.
Конструируем свои правила
Итак, у нас есть паттерны, которые наш алгоритм нашел в индикаторах и оценка, насколько хорошо эти паттерны действуют на новых данных.
Таким образом, мы хотим найти значения индикатора, где алгоритм находит сильный сигнал к покупке или продаже и где алгоритм более точен. Это позволит нам выделить для каждого индикатора значения, где достигаются как сильные сигналы, так и хорошая точность. Затем эти значения индикатора формируют наши правила.
Например, глядя на 20-периодный CCI, мы видим, что когда значения индикатора находятся в диапазоне от -100 до -290, алгоритм демонстрирует сильный сигнал к покупке и хорошую точность. Это говорит нам о том, что этот диапазон значений должен быть одним из правил для стратегии длинных позиций.
Значения индикатора и соответствующие правила обозначаются синим цветом для длинных позиций и желтым для коротких позиций.
Замечание: многие алгоритмы машинного обучения хорошо справляются с поиском взаимосвязей между индикаторами. Например, можно обнаружить, что если значения CCI меньше -200 и RSI меньше 25, то это очень сильный сигнал к продаже. Однако наивный байес не относится к таким алгоритмам. Термин "наивный" подчеркивает тот факт, что алгоритм работает в предположении, что каждый входной объект полностью независим от других. Поэтому мы анализируем только каждый индикатор в отдельности.
Сначала мы определим области, где мы можем найти сильные сигналы к покупке или продаже. Значения индикаторов и соответствующие правила обозначены синим цветом для длинных сигналов, и желтым - для коротких сигналов. Затем мы будем искать области, где алгоритм был точен и находился в диапазоне сильных покупок и продаж. И снова, значения индикаторов и соответствующие правила обозначены синим цветом для длинных сигналов, и желтым - для коротких сигналов
Затем мы можем записать значения наших индикаторов, которые мы выделили для длинных и коротких правил.
Правила для лонгов
ЕСЛИ
CCI20 выше -290 и ниже -100 И
RSI3 ниже 30 И
DEMA10cross выше -40 и ниже -20
ТО сигнал к покупке
Правила для шортов
ЕСЛИ
CCI20 выше 185 и ниже 325 И
RSI3 выше 50 И
DEMA10cross выше 10 и ниже 40
ТО сигнал к продаже
Нам необходимо проверить наши правила на тестовой выборке:
> #Изолируем трейды
> Long<-which(Validation$RSI3 < 30 & Validation$CCI > -290 & Validation$CCI < -100 & Validation$DEMA10c > -40 & Validation$DEMA10c < -20)
> # Создаем набор этих трейдов
> LongTrades<-Validation[Long,]
> #Тестируем точность
> LongAcc<-ifelse(LongTrades[,4]=="UP",1,0)
> # И наша точность на лонгах
> (sum(LongAcc)/length(LongAcc))*100
[1] 57.14286
> Short<-which(Validation$DEMA10c > 10 & Validation$DEMA10c < 40 & Validation$CCI > 185 & Validation$CCI < 325 & Validation$RSI3 > 50)
> ShortTrades<-Validation[Short,]
> ShortAcc<-ifelse(ShortTrades[,4]=="DOWN",1,0)
> # Наша точность на шотах
> (sum(ShortAcc)/length(ShortAcc))*100
[1] 60
> Long<-which(Validation$RSI3 < 30 & Validation$CCI > -290 & Validation$CCI < -100 & Validation$DEMA10c > -40 & Validation$DEMA10c < -20)
> # Создаем набор этих трейдов
> LongTrades<-Validation[Long,]
> #Тестируем точность
> LongAcc<-ifelse(LongTrades[,4]=="UP",1,0)
> # И наша точность на лонгах
> (sum(LongAcc)/length(LongAcc))*100
[1] 57.14286
> Short<-which(Validation$DEMA10c > 10 & Validation$DEMA10c < 40 & Validation$CCI > 185 & Validation$CCI < 325 & Validation$RSI3 > 50)
> ShortTrades<-Validation[Short,]
> ShortAcc<-ifelse(ShortTrades[,4]=="DOWN",1,0)
> # Наша точность на шотах
> (sum(ShortAcc)/length(ShortAcc))*100
[1] 60
Двигаемся к нашей окончательной статистике
> # Общее количество трейдов
> length(LongAcc)+length(ShortAcc)
[1] 46
> # Общая точность
> ((sum(ShortAcc)+sum(LongAcc))/(length(LongAcc)+length(ShortAcc)))*100
[1] 58.69565
> length(LongAcc)+length(ShortAcc)
[1] 46
> # Общая точность
> ((sum(ShortAcc)+sum(LongAcc))/(length(LongAcc)+length(ShortAcc)))*100
[1] 58.69565
Итого, у нас 46 трейдов (примерно 1 трейд за три дня на протяжении периода 153 дня), с точностью 59%.
Мы начали с общей теории о том, какие индиакторы являются самыми важными, и смогли быстро обнаружить паттерны в этих индикаторах, а затем выделить местонахождение с хорошей точностью сильных сигналов на покупку и продажу. Хотя наша выборка не очень большая, она может послужить основой для хорошей стратегии.
Анализ ассоциативных правил позволяет создавать хорошо подтверждаемые стратегии при использовании в качестве основы паттерны, найденные с помощью байесовского алгоритма и использовании тестовых выборок для подтверждения правильности найденных паттернов.
Мы можем использовать преимущества алгоритма машинного обучения, в то же время понимая логику, лежащую в основе стратегии, и легко можем применять эти правила в нашей торговле.
Комментариев нет:
Отправить комментарий