Что такое прогнозное моделирование?
Прогнозное моделирование - это процесс, используемый в прогнозной аналитике для создания статистической модели будущего поведения. Прогнозная аналитика - это область интеллектуального анализа данных, связанная с прогнозированием вероятностей и тенденций.
Предиктивное моделирование в трейдинге - это процесс моделирования, в котором мы прогнозируем вероятность результата, используя набор переменных-предикторов. В этом посте мы будем иллюстрировать прогнозное моделирование в R.
Кто это может использовать?
Прогнозные модели могут быть построены для различных активов, таких как акции, фьючерсы, валюты, товары и т. д. Например, мы можем построить модель для прогнозирования изменения цены акций на следующий день или модель для прогнозирования обменных курсов иностранных валют.
Как/зачем мы должны это делать?
Сила прогнозного моделирования может быть использована для принятия правильных инвестиционных решений и создания прибыльных портфелей.
Цель этой статьи
В этой статье мы подробно рассмотрим пошаговый процесс прогнозного моделирования в R, который используется для трейдинга с использованием различных технических индикаторов. Эта модель пытается предсказать изменение цены на следующий день (вверх/вниз) с помощью этих индикаторов и алгоритмов машинного обучения.
Шаг 1: Построение признаков
Наш процесс начинается с создания набора данных, который содержит функции, которые будут использоваться для составления прогнозов, и выходную переменную.
Сначала мы строим наш набор данных, используя необработанные данные, состоящие из 5-летнего ценового ряда для акций и индекса. Эти данные об акциях и индексах состоят из даты, открытия, максимума, минимума, закрытия и объема. Используя эти данные, мы вычисляем наши признаки на основе различных технических индикаторов (перечисленных ниже).
1 Force Index(FI)
2 William %R
3 Relative Strength Index(RSI)
4 Rate Of Change(ROC)
5 Momentum (MOM)
6 Average True Range(ATR)
Примечание. Прежде чем начать, убедитесь, что на вашем RStudio установлены и загружены следующие пакеты: Quantmode, PRoc, TTR, Caret, Corrplot, FSelector, rJava, kLar, randomforest, kernlab, rpart.
Код R:




Вычисленные технические индикаторы вместе с классом изменения цены (вверх/вниз) объединяются в единый набор данных.
Шаг 2: Понимание набора данных с использованием чисел и визуальных элементов
Наиболее важным условием для прогнозного моделирования является хорошее понимание набора данных. Понимание помогает в:
- преобразовании данных;
- выборе правильных алгоритмов машинного обучения;
- объяснении результатов, полученных из модели;
- улучшении ее точности.
Чтобы достичь такого понимания набора данных, вы можете использовать описательную статистику, такую как стандартное отклонение, среднее значение, асимметрия, наряду с визуализацией данных.
Код R:


Матрица корреляций

Шаг 3: Выбор признаков
Выбор признаков - это процесс выбора подмножества объектов, наиболее подходящих для построения модели, которые помогают создать точную модель прогнозирования. Существует широкий спектр алгоритмов выбора признаков, и они в основном попадают в одну из трех категорий:
1. Filter method - выбирает объекты, присваивая им оценку с использованием некоторой статистической меры.
2. Wrapper method - оценивает различные подмножества функций и определяет лучшее подмножество.
3. Embedded method - этот метод определяет, какие из функций обеспечивают наилучшую точность во время обучения модели.
В нашей модели мы будем использовать Filter method, использующий функцию random.forest.importance из пакета FSelector. Функция random.forest.importance оценивает важность каждого признака в классификации результата, то есть переменной класса. Функция возвращает data frame, содержащий имя каждого атрибута и значение важности, основываясь на среднем снижении точности.
Код R:


Вывод:

Теперь, чтобы выбрать лучшие объекты, используя значения важности, возвращаемые random.forest.importance, мы используем функцию cutoff.k, которая предоставляет k объектов с самыми высокими значениями важности.
В нашей модели мы выбрали десять из семнадцати признаков, которые были первоначально извлечены из ряда ценовых данных. Используя эти десять признаков, мы создаем набор данных, который будет использоваться в алгоритмах машинного обучения.
Шаг 4: Метод ресэмплинга
В прогнозном моделировании нам нужны данные для следующих процессов:
- для обучения модели;
- для проверки данных необходимо определить точность прогнозов, сделанных моделью.
Поскольку набор данных у нас ограничен, мы можем использовать методы повторной выборки, которые разделяют данные на обучающие и тестируемые выборки. В R доступны различные методы передискретизации, такие как разделение данных, метод bootstrap, перекрестная проверка в k-кратном порядке, повторная перекрестная проверка в k-кратном порядке и т. д.
В нашем примере мы используем метод перекрестной проверки кратности k, который разбивает набор данных на k подмножеств. Мы оставляем каждое подмножество в стороне, пока модель обучается на всех оставшихся подмножествах. Этот процесс повторяется, пока не будет определена точность для каждого экземпляра в наборе данных. Наконец, функция определяет общую оценку точности.
Код:


Шаг 5: Обучение различным алгоритмам
Существуют сотни алгоритмов машинного обучения, доступных в R, и определение используемой модели может сбить с толку новичков. Ожидается, что разработчики моделей попробуют различные алгоритмы, основанные на рассматриваемой проблеме, и имея практический опыт, вы сможете сделать правильный набор.
Несколько видов проблем:
- классификация;
- регрессия;
- кластеризация;
- извлечение правил.
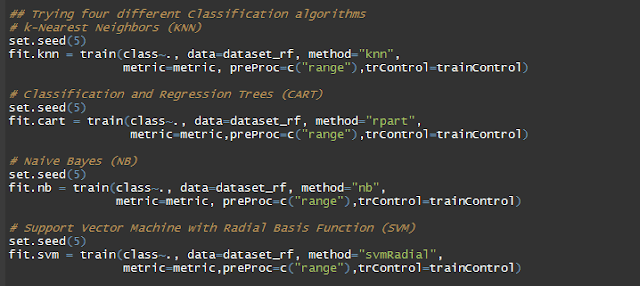
В нашем примере мы имеем дело с проблемой классификации, поэтому мы рассмотрим некоторые алгоритмы, предназначенные для решения таких проблем. Мы будем использовать следующие:
- k-Ближайших соседей (KNN);
- деревья классификации и регрессии (CART);
- наивный Байес (NB);
- машина опорных векторов с алгоритмами радиальной базисной функции (SVM).
Мы не будем подробно описывать работу этих алгоритмов, так как цель поста - детализировать этапы процесса моделирования, а не работу этих алгоритмов.
Мы используем функцию train из пакета caret, которая подходит для различных прогнозных моделей с использованием сетки параметров настройки. Например:

В приведенном выше примере мы используем алгоритм KNN, который указывается с помощью аргумента метода. class - выходная переменная, dataset_rf - набор данных, который используется для обучения и тестирования модели. Аргумент preProc определяет метод преобразования данных, а аргумент trControl определяет вычислительные нюансы функции train.

Шаг 6: Оценка моделей
Обученные модели оцениваются на предмет их точности в прогнозировании результата с использованием различных показателей, таких как точность, каппа, среднеквадратическая ошибка (RMSE), R2 и т.д.
Мы используем метрику «Accuracy» для оценки наших обученных моделей. Accuracy - это процент правильно классифицированных экземпляров от всех экземпляров в тестовом наборе данных. Мы использовали функцию resamples из пакета caret, которая берет обученные объекты и создает сводку с помощью функции summary.





Шаг 7: Настройка выбранных моделей
Как видно из метрики accuracy, все модели имеют точность в пределах 50-54%. В идеале мы должны попытаться настроить модели с более высокой точностью. Однако, для примера, мы выберем алгоритм KNN и попытаемся улучшить его точность, настроив параметры.
Настройка параметров
Мы настроим алгоритм KNN (параметр k) на значения в диапазоне от 1 до 10. Аргумент tuneGrid в функции train помогает определить точность в этом диапазоне при оценке модели.


Вывод:


Как видно из процесса настройки, точность алгоритма KNN не увеличилась, и она аналогична точности, полученной ранее. Вы также можете попробовать настроить другие алгоритмы на основе их соответствующих параметров настройки и выбрать алгоритм с максимальной точностью.
Заключение
На начальных этапах разработчики моделей могут попытаться работать с различными техническими индикаторами, создать модели на основе других классов активов и попробовать различные задачи прогнозного моделирования. Есть несколько очень хороших пакетов, которые упрощают прогнозное моделирование в R, а с опытом и практикой вы начнете создавать надежные модели для прибыльной торговли на рынках.
Комментариев нет:
Отправить комментарий