Временной ряд - это ряд точек данных, индексированных по времени, обычно с равными временными интервалами. Примерами временных рядов являются цены на акции, ежемесячная доходность, продажи компании и т. д. Временные ряды можно рассматривать как данные с целевой переменной (цена, доходность, объем продаж…) и только одной характеристикой: временем. Действительно, идея временных рядов заключается в том, что мы можем экстраполировать интересную информацию, анализируя поведение данной переменной во времени. Тогда, если появятся соответствующие выводы, в идеале будет возможно предсказать движение нашей переменной в будущем.
Однако, прежде чем анализировать временной ряд, как ожидалось выше, необходимо сделать некоторые предположения, поскольку интересующий нас объект является стохастическим. Чтобы понять случайный компонент временных рядов, давайте рассмотрим следующие определения.
Представьте, что у нас есть случайный процесс, то есть бесконечная последовательность случайных величин, которые определены в Ω (пространстве событий) и возвращают число в R.

Каждая случайная величина индексируется в фиксированный момент времени и имеет распределение вероятностей. Тем не менее, в каждый момент времени t будет показана только одна реализация нашего случайного процесса в t: у нас нет информации о других возможных реализациях. В результате мы не можем вычислить среднее (для каждого t) выборочное среднее нашего процесса, то есть:

Невозможность вычислить эту величину зависит от невозможности наблюдать реализацию X более чем для одного ω одновременно. Мы можем визуализировать это ограничение на следующем примере:

В каждый момент времени t у нас есть распределение вероятностей нашей случайной величины Xt (синие точки), но мы можем наблюдать только одну реализацию (оранжевая точка). Единственный способ вычислить среднее значение выборки поперечного сечения - это нарисовать для одного и того же явления несколько временных рядов, но это, очевидно, невозможно, поскольку предполагает возможность вернуться в прошлое.
В качестве альтернативы мы можем изменить нашу структуру и вычислить выборочное среднее значение нашего процесса во времени, что означает:

Мы хотим, чтобы эта величина сходилась к истинному среднему значению временного ряда, и мы можем добиться этого при двух условиях.
Стационарность
Мы хотим, чтобы среднее значение нашего временного ряда было инвариантным во времени, это означает:

Кроме того, автоковариация двух или более элементов процесса должна зависеть только от относительного расстояния между ними во времени. В формуле:

Мы также можем усилить это условие, введя так называемую сильную стационарность, которая возникает, когда совместное распределение двух или более элементов зависит только от их относительного расстояния. Обратите внимание, что сильная стационарность подразумевает слабую стационарность при условии, что ковариация существует.
Оценим разницу между нестационарным процессом и стационарным (данные доступны здесь):
import pandas as pd
ts = pd.read_csv('sales-of-shampoo-over-a-three-ye.csv') ts.set_index('Month', inplace=True)
ts.plot()

Здесь, если мы вычислим выборочное среднее по времени, мы получим нечто, что переоценивает истинные значения в первые периоды и занижает их в последние периоды:
import matplotlib.pyplot as plt
m = ts.mean()
ts.plot()
plt.axhline(y=m[0], color='red')

С другой стороны, если мы возьмем первую разность этого ряда, мы получим нечто более стационарное:
diff=ts.diff()
diff.plot()

И, вычислив среднее значение, мы можем увидеть, насколько это более точное приближение к нашему ряду:
m = diff.mean()
diff.plot()
plt.axhline(y=m[0], color='red')

Итак, достаточно ли стационарности для нашего выборочного среднего, чтобы быть хорошим приближением к реальному среднему? Ответ - нет, поскольку для достижения этой цели нам нужно еще одно условие.
Эргодичность
С помощью эргодичности мы просим наш процесс двигаться вокруг среднего. В противном случае высок риск иметь искаженное среднее значение, стремящееся к «области», где процесс застревает.
Чтобы дать вам интуитивное понимание, давайте рассмотрим пример, в котором процесс стационарен, но не эргодичен. Представьте себе случайный процесс, в котором каждый X является двоичной случайной величиной Бернулли, следовательно, он принимает значения 1 или 0. Кроме того, наш процесс таков, что он принимает значение (0 или 1) в начальный момент и остается неизменным на этом значении навсегда. Следовательно, наш временной ряд будет выглядеть как прямая линия либо с 1, либо с 0. Мы знаем, что истинное среднее значение нашего процесса находится в диапазоне от 0 до 1, однако среднее, вычисленное во времени, всегда будет возвращать 1 или 0.
Идея эргодичности заключается в том, что, собирая все больше и больше наблюдений, мы продолжаем узнавать что-то новое о процессе. Другими словами, если я выберу две случайные переменные процесса, которые находятся достаточно «далеко друг от друга», их распределения должны быть независимыми. Если вы подумаете о приведенном выше примере, то теперь вы можете увидеть, что этот процесс явно не эргодичен: независимо от того, сколько наблюдений мы собираем, мы не получаем никакой дополнительной информации, поскольку все известно с самого начала (из начального значения, взятого по нашему процессу).
Формальное определение эргодичности следующее:

Для любых двух ограниченных функций f: Rk-> R, g: Rl-> R.
Комбинируя стационарность с эргодичностью, справедливо следующее соотношение:
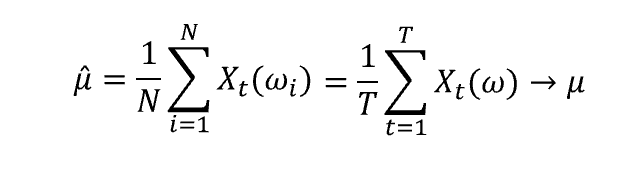
Стационарность и эргодичность являются основными допущениями для выполнения анализа временных рядов, и важно иметь в виду, как их достичь и как проверить, выполняются ли они.
Если вас интересует анализ временных рядов, я прилагаю ссылки на некоторые предыдущие статьи, которые я написал по этой теме, как на R, так и на Python.
Комментариев нет:
Отправить комментарий